
now some progress on fmnist as well
Showing
- dev/rebuttal/6zGr.md 4 additions, 9 deletionsdev/rebuttal/6zGr.md
- dev/rebuttal/ZaU8.md 1 addition, 1 deletiondev/rebuttal/ZaU8.md
- dev/rebuttal/global.md 8 additions, 34 deletionsdev/rebuttal/global.md
- dev/rebuttal/pekM.md 10 additions, 12 deletionsdev/rebuttal/pekM.md
- dev/rebuttal/uCjw.md 5 additions, 7 deletionsdev/rebuttal/uCjw.md
- dev/rebuttal/www/mnist_2to3_16.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_2to3_16.png
- dev/rebuttal/www/mnist_2to3_17.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_2to3_17.png
- dev/rebuttal/www/mnist_2to3_18.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_2to3_18.png
- dev/rebuttal/www/mnist_2to3_19.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_2to3_19.png
- dev/rebuttal/www/mnist_2to3_20.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_2to3_20.png
- dev/rebuttal/www/mnist_4to1_11.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_4to1_11.png
- dev/rebuttal/www/mnist_4to1_12.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_4to1_12.png
- dev/rebuttal/www/mnist_4to1_13.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_4to1_13.png
- dev/rebuttal/www/mnist_4to1_14.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_4to1_14.png
- dev/rebuttal/www/mnist_4to1_15.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_4to1_15.png
- dev/rebuttal/www/mnist_5to8_21.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_5to8_21.png
- dev/rebuttal/www/mnist_5to8_22.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_5to8_22.png
- dev/rebuttal/www/mnist_5to8_23.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_5to8_23.png
- dev/rebuttal/www/mnist_5to8_24.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_5to8_24.png
- dev/rebuttal/www/mnist_5to8_25.png 0 additions, 0 deletionsdev/rebuttal/www/mnist_5to8_25.png
dev/rebuttal/www/mnist_2to3_16.png
0 → 100644
{kind=link}

31.2 KiB
dev/rebuttal/www/mnist_2to3_17.png
0 → 100644
{kind=link}

31.8 KiB
dev/rebuttal/www/mnist_2to3_18.png
0 → 100644
{kind=link}

32.9 KiB
dev/rebuttal/www/mnist_2to3_19.png
0 → 100644
{kind=link}

31.7 KiB
dev/rebuttal/www/mnist_2to3_20.png
0 → 100644
{kind=link}

31 KiB
dev/rebuttal/www/mnist_4to1_11.png
0 → 100644
{kind=link}

29.6 KiB
dev/rebuttal/www/mnist_4to1_12.png
0 → 100644
{kind=link}
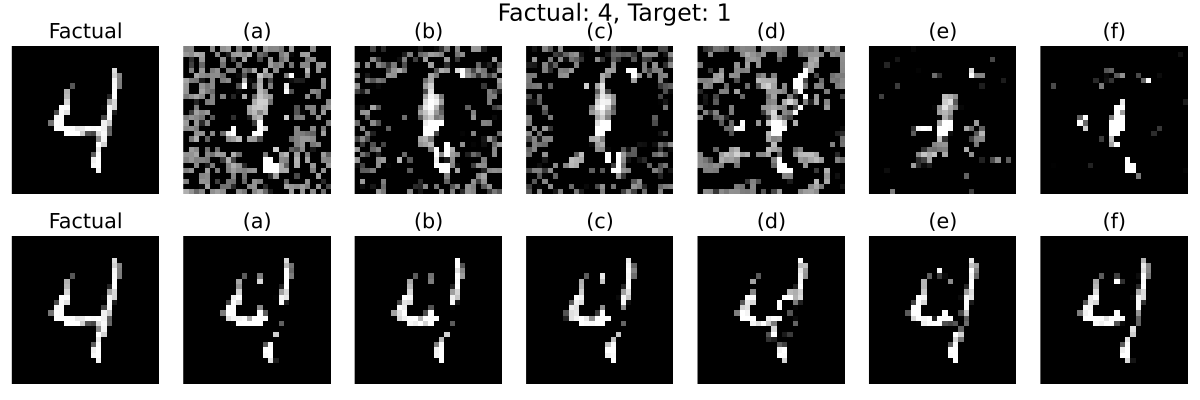
29.7 KiB
dev/rebuttal/www/mnist_4to1_13.png
0 → 100644
{kind=link}
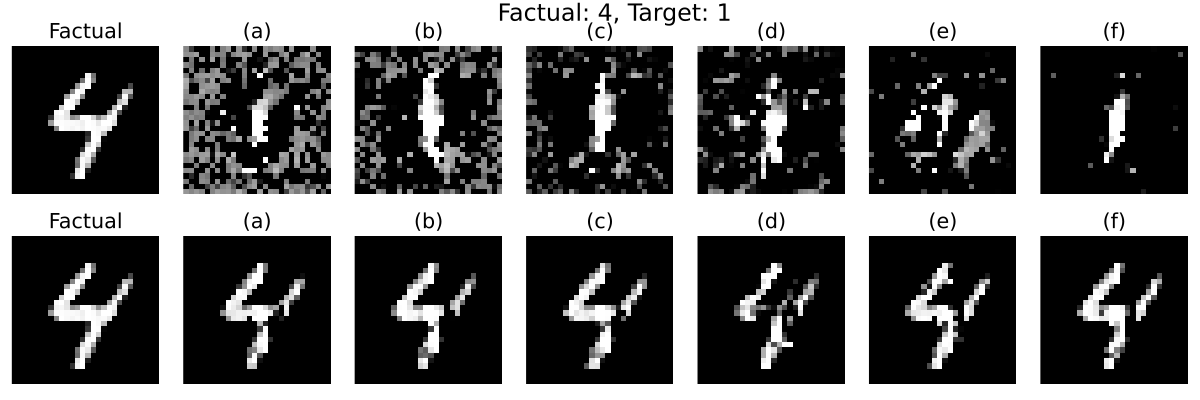
30.6 KiB
dev/rebuttal/www/mnist_4to1_14.png
0 → 100644
{kind=link}

31.4 KiB
dev/rebuttal/www/mnist_4to1_15.png
0 → 100644
{kind=link}

30.7 KiB
dev/rebuttal/www/mnist_5to8_21.png
0 → 100644
{kind=link}

30.8 KiB
dev/rebuttal/www/mnist_5to8_22.png
0 → 100644
{kind=link}

31.7 KiB
dev/rebuttal/www/mnist_5to8_23.png
0 → 100644
{kind=link}

29.4 KiB
dev/rebuttal/www/mnist_5to8_24.png
0 → 100644
{kind=link}

30.6 KiB
dev/rebuttal/www/mnist_5to8_25.png
0 → 100644
{kind=link}

31.4 KiB